您现在的位置是:首页 > 后端 > PHP PHP
视图、索引、存储过程优缺点
 2020-05-17【PHP】2946人已围观
2020-05-17【PHP】2946人已围观
简介1.视图(1).什么是视图?视图(View)作为一种数据库对象,为用户提供了一个可以检索数据表中的数据方式。用户通过视图来浏览数据表中感兴趣的部分或全部数据,而数据的物理存储位置仍然在表中。视图是一个虚拟表,并不代表任何物理数据,只是用来查看数据的窗口而已。视图并不是以一组数据的形式存储在数据库中,数据库中只存储视图的定义,而不存储视图对应的数据,这些数据仍存储在导出视图的基本表中。当基本表中的数据发生变化时,从视图中查询出来的数据也随之改变。视图中的数据行和列都是来自于基本表,是在视图被引用时动态生成的
1.视图
(1).什么是视图?
视图(View)作为一种数据库对象,为用户提供了一个可以检索数据表中的数据方式。用户通过视图来浏览数据表中感兴趣的部分或全部数据,而数据的物理存储位置仍然在表中。
视图是一个虚拟表,并不代表任何物理数据,只是用来查看数据的窗口而已。视图并不是以一组数据的形式存储在数据库中,数据库中只存储视图的定义,而不存储视图对应的数据,这些数据仍存储在导出视图的基本表中。当基本表中的数据发生变化时,从视图中查询出来的数据也随之改变。
视图中的数据行和列都是来自于基本表,是在视图被引用时动态生成的。使用视图可以集中、简化和制定用户的数据库显示,用户可以通过视图来访问数据,而不必直接去访问该视图的基本表。
视图由视图名和视图定义两个部分组成。视图是从一个或多个表导出来的表,它实际上是一个查询结果,视图的名字和视图对应的查询存储在数据字典中。
(2).视图的优缺点?
<1>.视图的优点
A.数据安全性。
对不同的用户定义不同的视图,使用户只能看到与自己有关的数据。数据库授权命令可以使每个用户对数据库的检索限制到特定的数据库对象上,但不能授权到数据库特定行和特定的列上。通过视图,用户可以被限制在数据的不同子集上。
B.查询简单化。
为复杂的查询建立一个视图,用户不必输入复杂的查询语句,只需针对此视图做简单的查询即可。那些被经常使用的查询可以被定义为视图,从而使用户不必为以后的操作每次都指定全部的条件。
C.逻辑数据独立性。
视图可以使应用程序和数据库表在一定程度上独立。如果没有视图,应用一定是建立在表上的。有了视图之后,程序可以建立在视图之上,从而程序与数据库表被视图分割开来。
对于视图的操作,例如,查询只依赖于视图的定义,当构成视图的基本表需要修改时,只需要修改视图定义中的子查询部分,而基于视图的查询不用改变。
<2>.视图的缺点
A.性能。
SQL Server必须把视图的查询转化成对基本表的查询,如果这个视图是由一个复杂的多表查询所定义,那么,即使是视图的一个简单查询,SQL Server也把它变成一个复杂的结合体,需要花费一定的时间。
B.修改限制。
当用户试图修改视图的某些行时,SQL Server必须把它转化为对基本表的某些行的修改。事实上,当从视图中插入或者删除时,情况也是这样。对于简单视图来说,这是很方便的,但是,对于比较复杂的视图,可能是不可修改的,这些视图有如下特征:
a.有UNIQUE等集合操作符的视图。
b.有GROUP BY子句的视图。
c.有诸如AVG\SUM\MAX等聚合函数的视图。
d.使用DISTINCT关键字的视图。
e.连接表的视图(其中有些例外)
(3).创建视图的限制:
在创建视图时,还要注意试图必须满足以下几点限制:
<1>.不能将规则或者DEFAULT定义关联于视图。
<2>.定义视图的查询中不能含有ORDER BY\COMPURER\COMPUTER BY 子句和INTO关键字
<3>.如果视图中某一列是一个算术表达式、构造函数或者常数,而且视图中两个或者更多的不同列拥有一个相同的名字(这种情况通常是因为在视图的定义中有一个连接,而且这两个或者多个来自不同表的列拥有相同的名字),此时,用户需要为视图的每一列指定列的名称。
参考博客:
《使用SQL Server视图的优缺点》
2.索引
(1).什么是索引?
索引是以表列为基础的数据库对象,它保存着表中排序的索引列,并且记录了索引列在数据表中的物理存储位置,实现了表中数据的逻辑排序,其主要目的是提高SQL Server系统的性能,加快数据的查询速度和减少系统的响应时间。索引通过记录表中的关键值指向表中的记录,这样数据库引擎就不用扫描整个表而定位到相关的记录。相反,如果没有索引,则会导致SQL Server搜索表中的所有记录,以获取匹配结果。
索引除了可以提高查询表内数据的速度以外,还可以使表和表之间的连接速度加快。例如,在实现数据参照完整性时,可以将表的外键制作为索引,这样将加速表与表之间的连接。
(2).索引的分类
有3种索引类型:聚集索引、非聚集索引和唯一索引。如果表中存在聚集索引,则非聚集索引使用聚集索引来加快数据查询。
<1>.聚集索引
聚集索引会对表和视图进行物理排序,所以这种索引对查询非常有效,在表和视图中只能有一个聚集索引。当建立主键约束时,如果表中没有聚集索引,SQL Server会用主键列作为聚集索引键。可以在表的任何列或列的组合上建立索引,实际应用中一般定义成主键约束的列建立聚集索引。
<2>.非聚集索引
非聚集索引不会对表和视图进行物理排序。如果表中不存在聚集索引,则表示未排序的。在表或视图中,最多可以建立250个非聚集索引,或者249个非聚集索引和1个聚集索引。
<3>.唯一索引
唯一索引不允许两行具有相同的索引值。只要列中数据是唯一的,就可在同一个表上创建一个唯一的聚集索引。如果必须实施唯一性以确保数据的完整性,则应在列上创建UNIQUE或PRIMARY KEY约束,而不要创建唯一索引。
(3).使用索引的代价
虽然索引有很多优点,但索引的存在也让系统付出了一定的代价。创建索引和维护索引都会消耗时间,当对表中的数据进行增加、删除和修改操作时,索引就要进行维护,否则索引的作用就会下降;另外,每个索引都会占用一定的物理空间,如果占用的物理空间过多,就会影响到整个SQL Server系统的性能。
(4).建立索引的原则
创建索引虽然可以提高查询速度,但是它是牺牲一定的系统性能。因此,在创建时,哪些列适合创建索引,哪些列不适合创建索引,需要进行判断,具体以下原则:
<1>.有主键的数据列要建立索引。因为主键可以加速定位到表中的某一行。
<2>.有外键的数据列要建立索引。外键列通常用于表与表之间的连接,在其上创建索引可以加快表间的连接。
<3>.对于经常查询的数据列最好建立索引。
A.对于需要在指定范围内快速或频繁查询的数据列,因为索引已经排序,其指定的范围是连续的,查询可以利用索引的排序,加快查询的时间。
B.经常用在WHERE子句中的数据列,将索引建立在WHERE子句的集合过程中,对于需要加速或频繁检索的数据列,可以让这些经常参与查询的数据列按照索引的排序进行查询,加快查询的时间。
<4>.对于那些查询中很少涉及的列、重复值比较多的列不要建立索引。
例如,在查询中很少使用的列,有无索引并不能提高查询的速度,相反增加了系统维护时间和消耗了系统空间。
<5>.对于定义为text、image和bit数据类型的列不要建立索引。因为这些数据类型的数据列的数据量要么很大、要么很小,不利于使用索引。
参考博客:
《SQLServer索引调优实践》
《SQL Server索引维护指导(1)》
《详细讲解SQL Server索引的性能问题》
3.存储过程
(1).什么是存储过程?
当开发一个应用程序时,为了易于修改和扩充,经常会将负责不同功能的语句集中起来而且按照用途分别放置,以便能够反复调用,而这些独立放置且拥有不同功能的语言,即是“过程”(Procedure)。
存储过程(Stored Producedures)是一组为完整特定功能的SQL语句集,经编译后存储在数据库中。用户通过指定存储过程的名字给出参数(如果该存储过程带有参数)来执行它。
它能够包含执行各种数据库操作的语句,并且可以调用其他的存储过程;能够接受输入参数,并以输出参数的形式将多个数据值返回给调用程序(Calling Procedure)或批处理(Batch);向调用程序或批处理返回一个状态值,以表明成功或失败(以及失败的原因)。
(2).存储过程的优点
<1>.存储过程优点
A.执行速度快。
存储过程只在创造时进行编译,已经通过语法检查和性能优化,以后每次执行存储过程都不需再重新编译,而我们通常使用的SQL语句每执行一次就编译一次,所以使用存储过程可提高数据库执行速度。
B.允许组件式编程。
经常会遇到复杂的业务逻辑和对数据库的操作,这个时候就会用SP来封装数据库操作。当对数据库进行复杂操作时(如对多个表进行Update,Insert,Query,Delete时),可将此复杂操作用存储过程封装起来与数据库提供的事务处理结合一起使用。只需创建存储过程一次并将其存储在数据库中,以后即可在程序中调用该过程任意次。在代码上看,SQL语句和程序代码语句的分离,可以提高程序代码的可读性。
存储过程可以设置参数,可以根据传入参数的不同重复使用同一个存储过程,从而高效的提高代码的优化率和可读性。
C.减少网络流量。
一个需要数百行Transact-SQL代码的操作由一条执行过程代码的单独语句就可实现,而不需要在网络中发送数百行代码。
对于同一个针对数据库对象的操作,如果这一操作所涉及到的T-SQL语句被组织成一存储过程,那么当在客户机上调用该存储过程时,网络中传递的只是该调用语句,否则将会是多条SQL语句。从而减轻了网络流量,降低了网络负载。
D.提高系统安全性。
可将存储过程作为用户存取数据的管道。可以限制用户对数据表的存取权限,建立特定的存储过程供用户使用,避免非授权用户对数据的访问,保证数据的安全。
<2>.存储过程缺点:
A.移植性差。依赖于数据库厂商,难以移植(当一个小系统发展到大系统时,对数据库的要求也会发生改变);
B.难以调试、维护。业务逻辑大的时候,封装性不够,难调试难以维护;
C.服务器不能负载均衡。复杂的应用用存储过程来实现,就把业务处理的负担压在数据库服务器上了。没有办法通过中间层来灵活分担负载和压力.均衡负载等。
(3).存储过程分类
<1>.系统存储过程
系统存储过程(System Stored Procedures)主要存储在master数据库中,并以sp_为前缀,并且系统存储过程主要是从系统表中获取信息,从而为系统管理员管理SQL Server提供支持。
<2>.本地存储过程
本地存储过程(Local Stored Procedures)也就是用户自行创建在用户数据库中的存储过程。事实上一般所说的存储过程值得就是本地存储过程。用户创建的存储过程是由用户创建并能完成某一特定功能(如查询用户所需的数据信息)的存储过程。
<3>.临时存储过程
临时存储过程(Temporary Stored Procedures)可分为以下两种:
A.本地临时存储过程
如果在创建存储过程中,以井号(#)作为其名称的第一个字符,则该存储过程将成为一个存放在tempdb数据库中的本地临时存储过程(例如,CREATE PROCEDURE #book_proc.....)。本地临时存储过程只有创建它的连接的用户才能够执行它,而且一旦这位用户断开与SQL Server的连接,本地临时存储过程就会自动删除,当然,这位用户也可以在连接期间用DROP PROCEDURE命令删除多创建的本地临时存储过程。
B.全局临时存储过程
如果在所创建的存储过程名称是以两个井号(# #)开始,则该存储过程将成为一个存储在tempdb数据库中的全局临时存储过程,如果没有,便立即将全局临时存储过程删除;如果有,SQL Server会让这些执行中的操作继续进行,但是不允许任何用户再执行全局临时存储过程,等到所有未完成的操作执行完毕后,全局临时存储过程就会自动删除。
由于全局临时存储过程能够被所有的连接用户使用,因此,必须注意其名称不能和其他连接所采用的名称相同。
<4>.远程存储过程
远程存储过程(Remote Stored Procedures)是位于远程服务器上的存储过程,通常可以使用分布式查询和EXECUTE命令执行一个远程存储过程。
<5>.扩展存储过程
扩展存储过程(Extended Stored Procedures)是用户可以使用外部程序语言编写的存储过程。扩展存储过程在使用和执行上与一般的存储过程完全相同。可以将参数传递给扩展存储过程,扩展存储过程也能够返回结果和状态值。
为了区别,扩展存储过程的名称通常以xp_开头。扩展存储过程是以动态链接库(DLLS)的形式存在,能让SQL Server动态的装载和执行。扩展存储过程一定要存储在系统数据库master中。
关注博客,更多精彩分享,敬请期待!
Tags:
很赞哦! (0)
相关文章
随机图文

css动画
> 在CSS动画中,如果你想让元素的 border-radius 从50%逐渐变为0%,你可以使用 @keyframes 规则来定义这一变化过程。以下是一个简单的示例: ```css /* 定义一个动画 */ @keyframes borderRadiusChange { 0% { border-radius: 50%; } 100% { border-radius: 0; } } /* 将动画应用到某个元素上 */ .someElement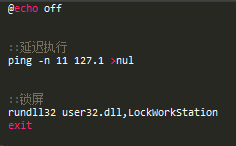
bat锁屏和熄屏 windows
bat锁屏和熄屏 windows
PHP中判断字符串是否含有中文
## 判断全是中文 > 方法一 ``` $str = '吾爱编程'; if (preg_match_all("/^([\x81-\xfe][\x40-\xfe])+$/", $str, $match)) { echo '全部是中文'; } else { echo '不全是中文'; } ``` > 方法二 ``` $str="'吾爱it编程"; if(!eregi("[^\x80-\xff]","$str")){ echo "全是中文";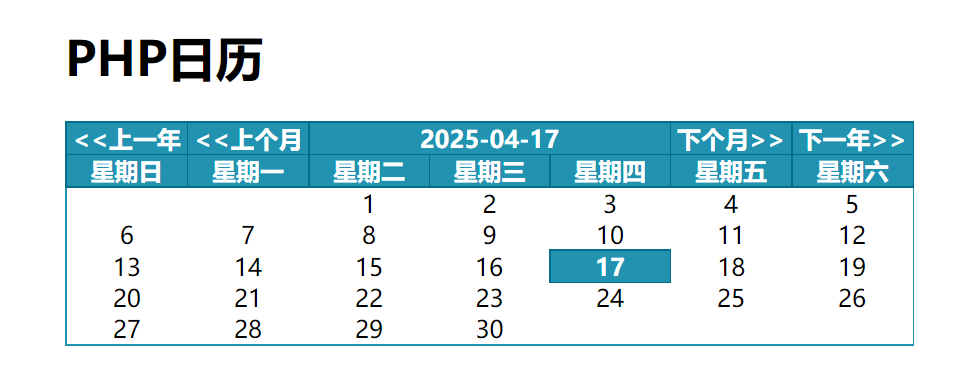
PHP日历
PHP日历小案例





